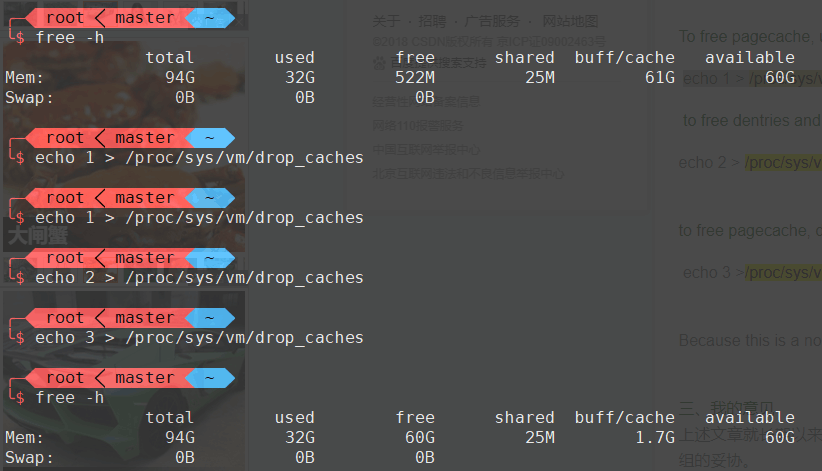
Linux中的buff/cache可以被手动释放,释放缓存的代码如下:
echo 1 > /proc/sys/vm/drop_caches;
echo 2 > /proc/sys/vm/drop_caches;
echo 3 > /proc/sys/vm/drop_caches;结论说完了,下面开始讲故事了
刚刚开始使用linux的时候,知道查看内存的命令是free,但是不知道出来的几列数值是什么意思,前辈曾经教我说最后一列available列出的才是真正的可用的空闲内存,free加上buff/cache等于available,我当然记住了这个结论,但是从结果看来我并没有理解这个结论。
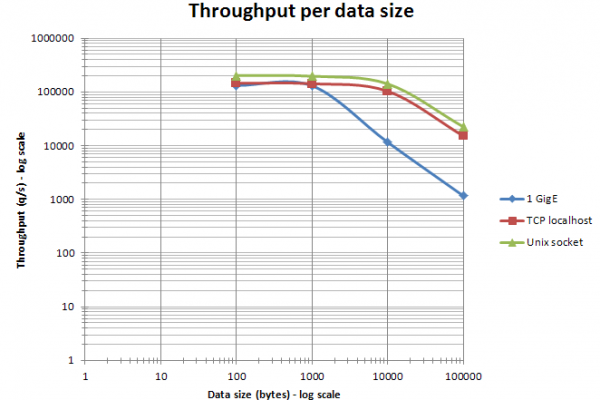
$ free -h
total used free shared buff/cache available
Mem: 94G 31G 60G 25M 2.3G 61G
Swap: 0B 0B 0B在大约8个月前,公司启动了软件容器化的进程,我作为公司容器化的技术支持,制定了第一套K8s集群的硬件设施要求,由于担心金额过高批不下来,第一期只计划购买了两台性能比较好的机器,一台作为master兼worker,令一台作为纯worker,两台机器总共配置了200GB内存,我本以为这些内存足够使用了,然而在过去的八个月里,这几台机器的内存很快的就被测试环境跑满了。
这导致测试服务的部署开始断断续续的出现一些恼人的问题,比如会触发OOMkiller,然后杀掉一些有状态的软件。比较倒霉的时候还会杀掉集群的SDN软件flanneld,触发一个3.x版本上的内核bug,导致整个节点的容器沙箱无响应,只能重启机器。虽然这个沙箱无响应的问题后来通过升级4.14内核解决了,但根本的内存瓶颈问题还是没有解决。
不过因为我一直有其他的开发任务,而且这个环境大多数时间用的还算正常,扛得下压力,所以我没有深究过。一直到前几天测试想要部署一套新的环境时,测试部的领导找到我,咨询我再申请几台机器应该要什么配置的时候,我才打算查一查是怎么回事。

ssh登陆到K8s的节点上一看,发现可用内存还是很多的,但是大多数都被缓存申请过去了,比例已经达到了令人发指的2/3。但按理说这不会造成问题,因为linux会在内存占用较高的时候自动释放这些内存,那问题是什么呢?
buff/cache是用于加速程序运行的,有一些硬盘/网络上的数据加载的速度比较慢,因此会被缓存到高速的内存中,以免去重复加载的时间消耗。buff/cache在内存占用过高的时候会被系统自动清理, 但是这种清缓存的工作也并不是没有成本。清缓存必须保证cache中的数据跟对应文件中的数据一致,所以伴随着cache清除的行为的,一般都是要做大量硬盘读写的。因为内核要对比cache中的数据和对应硬盘文件上的数据是否一致,如果不一致需要写回,之后才能回收。 硬盘读写就意味着高延迟,这个延迟通常会达到几毫秒到数秒。
在正常的场景中,这种延迟是不会有太大问题的,因为正常的服务都是一点一点开辟内存的,而且受制于人的操作速度,服务也一般不会突然全部启动。然而对于容器部署就会遇到一个问题,容器开辟内存使用的是Cgroup。如果说进程开内存像买房子,Cgroup开内存就比较像圈地,如果给容器指定了500MB内存,那这个容器启动,系统里就有500GB内存被划走到某个名下,不给别人用了。(后来对Cgroup的了解深入了一些后发现这个结论是错误的,Cgroup的request并不会直接把资源划走。这个问题本质上也不是由缓存占用过大导致的,而是由于flannel官方的manifest为flanneld设置了过小的cgroup内存限制)如果这些容器恰好还是批量部署的,那机器的内存申请量就会出现一个阶梯式的激增,这时候系统就只能祭出杀器——OOMKiller。这样就造成了一些部署的问题。
最后由于测试环境对效率的要求并不高,所以我决定牺牲效率换内存空闲量,建了一个清理缓存的定时任务,经过一周的测试,这两台机器上没有再出现过OOMkill。

不过虽然问题已经解决了,领导还是打算阔一倍内存,贫穷真的限制了我的想象力。