今天在和同事聊天时聊起了分布式协议,我非常本能的讲出了“要想实现强一致性需要依赖raft/paxos一类的算法”,当时同事就反驳了我,说raft应该不算强一致性,将entries同步到集群中的所有成员才算是强一致性。
这个反驳让我一惊,紧接着心里就没底了,回忆了一下,自己好像确实没有明确的在哪里看到过明确说raft是强一致性算法,也完全记不清自己为什么会产生这样的认知,大脑一片空白之际,只好回应说:如果真是你说的那样的话,那可能raft算是最终一致性吧。
TL;DR
先说结论,根据强一致性的定义,Raft是名副其实的强一致性算法
强与弱一致性
下面的定义摘自剑桥大学的slide
Strong consistency – ensures that only consistent state can be seen.
- All replicas return the same value when queried for the attribute of an object All replicas return the same value when queried for the attribute of an object. This may be achieved at a cost – high latency.
Weak consistency – for when the “fast access” requirement dominates.
- update some replica, e.g. the closest or some designated replica
- the updated replica sends up date messages to all other replicas.
- different replicas can return different values for the queried attribute of the object the value should be returned, or “not known”, with a timestamp
- in the long term all updates must propagate to all replicas …….
- consider failure and restart procedures,
- consider order of arrival,
- consider possible conflicting updates consider possible conflicting updates
强一致性集群中,对任何一个节点发起请求都会得到相同的回复,但将产生相对高的延迟。而弱一致性具有更低的响应延迟,但可能会回复过期的数据,最终一致性即是经过一段时间后终会到达一致的弱一致性。
其实可以看出,最终一致性的要求非常低,除了像gossip这样明确以最终一致性为卖点的协议外,包括redis主备、mongoDB、乃至mysql热备都可以算是最终一致性,甚至如果我记录操作日志,然后在副本故障了100天之后手动在副本上执行日志以达成一致,也算是符合最终一致性的定义,关于这一点之前在和PingCAP的东旭老师见面时,他曾经非正式的吐槽过,说最终一致性在他看来就是没有一致性,因为没人可以知道什么时候算是最终。当时我还不太能体会到这句话的涵义,现在觉得这个说法不失公允。
为什么Raft是强一致性
根据上一节中对强一致性的定义,强一致性强调的是强一致性读,既不会读到过期的结果。但并不要求将每个写请求复写到集群中的每个节点上。
Raft是符合这个强一致性定义的,通过每次读取前都先由leader确认无落后的Committed entries,Raft保证任何时候都不会返回过期的数据。
下面这段描述来源于Raft的论文,出处所在的段落描述了Raft对强一致性读的要求和基本的实现思路。
Raft handles this by having the leader exchange heartbeat messages with a majority of the cluster before responding to read-only requests.
另有一段来自StackOverflow的答案 How raft algorithm maintains strong read consistency
Raft
最后再来聊聊Raft吧。
在我第一次写分布式程序的时候,曾经仔细考虑过底层应该依赖哪种数据库,考察过TIDB和redis。后来因为是要求300ms内响应的实时应用程序,所以选择了低延迟的redis。
当时顺便花了点时间读了raft的论文,可惜项目启动开发时才看到集群配置变更的可靠性证明那里,算是半途而废。Raft挺有意思的,今天借机好好整理消化一下之前读完的内容。
Raft一切可靠性都离不开election的可靠性。
在一个Raft集群中,一个成员的log必须不落后于集群多数成员且与他们内容一致,才可能被选举成为leader,而committed的log一定已经被复制到了多数成员,因此任何时候只会有一个版本的committed log,不会出现分叉。这个特性保证了log的历史是一致的。
而多数成员接受机制保证了在包括分区在内的任何情况下,一个Raft集群在一个term中最多只能产生一个有实权进行entries append的leader,这意味着同一时刻最多只有一个成员会更改term和index。这又保证了新增的log是一致的。
上面的两段话分别对应了下图的Election Safety和Leader Append-Only,我认为这两个保证是核心,而剩下的三个保证是对前两个保证中边界条件的补充。

这两个保证很阴险,它覆盖了很多种特殊情况。 比如,实际上可能会出现若干个自以为是leader的假leader,但由于这些假leader没有leader的append entries权力,因此没有影响。又比如论文中这个著名的例子,展示了一个已经replicated到多数成员但是没有被committed的log是如何被新的leader改写。
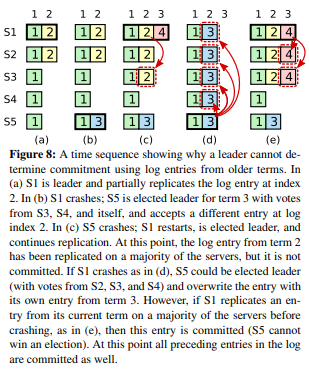
Election Safety也体现着一个哲学,就是leader权力的本质并不是leader自身的identity,而是他的公信力,leader privilege的本质是成员的共识。也就是所谓的权力是由人民赋予(草)。
是这样的,经常有人会混淆这个概念的,强一致性的要求是说 Raft 的各个节点提供服务的时候状态一致,至于你用 Raft 做什么服务发现之类,服务端下线之后不能被及时发现,那不属于一致性的部分。。
。。。可以做一下6.824的lab
我另外还看了大佬的19年总结,唉,我一直在小公司,一直在学,但感觉自己完全不知道方向在哪