
TL; DR
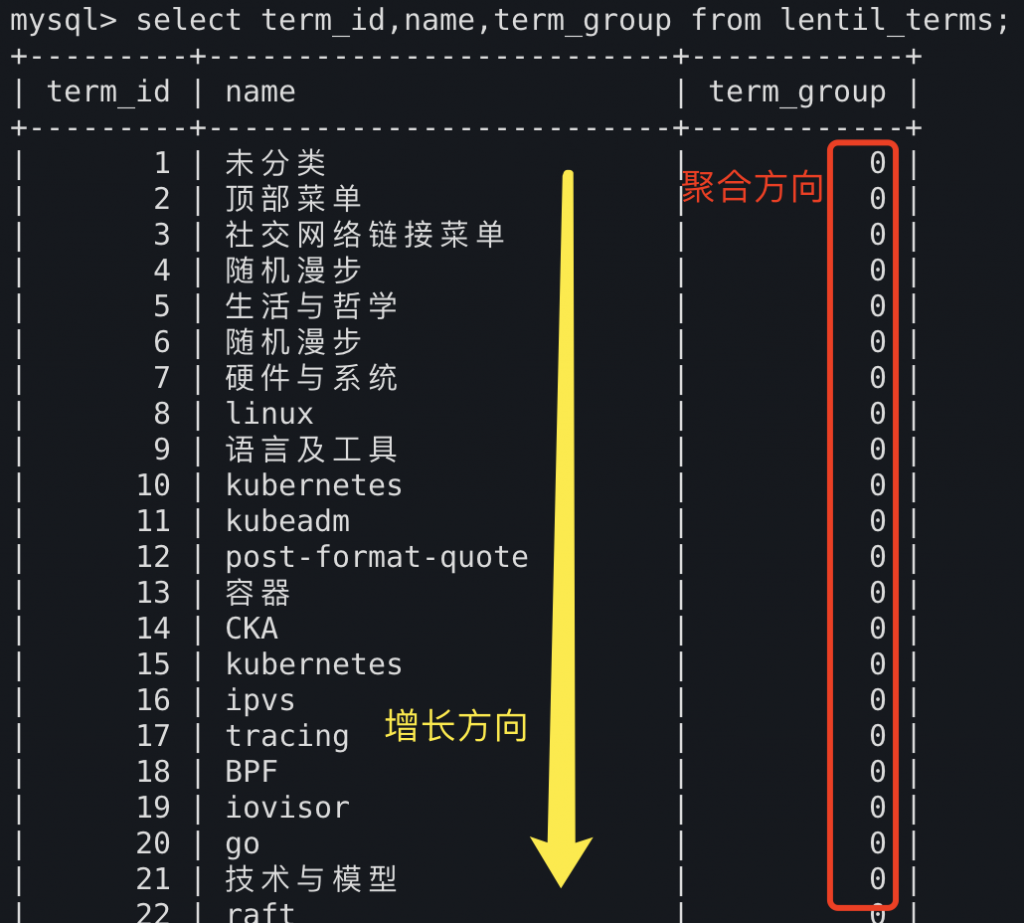
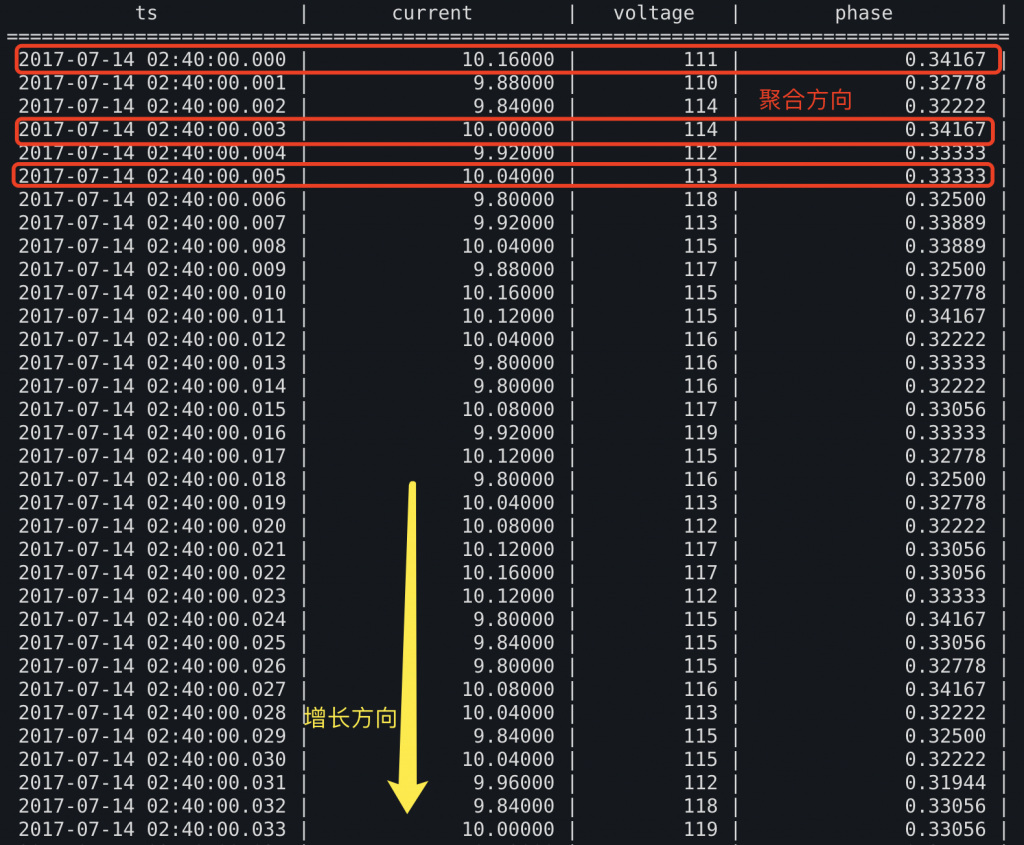
传统的SQL范式面对的场景中,数据表的增长方向与数据的主要聚合方向相同。而对时序分析的场景来说,数据的增长方向与主要聚合方向不同。这是SQL无法胜任TSDB和时序分析查询的根本原因。
退一步,进两步

InfluxDB一直是开源TSDB中最受关注的热点项目,其热度甚至远超过Kdb+这类闭源商业时序数据库。InfluxDB最初发起于2013年10月22日,并最早于2014年发布了第一个版本v0.8,在最初的一系列发布版本中,InfluxDB提供的是一种名为InfluxQL的类SQL查询语言。
在接下来的时间里,InfluxDB社区受到了一些挑战:他们接到了非常多的Feature request,他们认为这些特性是好的并希望加以实现。

但当他们尝试将这些特性加入到InfluxQL中的时候,问题出现了:一方面开发的过程非常艰难和痛苦;另一方面,这些修改让InfluxQL这个类SQL语言越来越不像SQL。很多SQL的规范和特性被破坏,开始有非常熟悉SQL的开发者反馈他们无法用InfluxQL得到符合直觉的查询结果。
2015年秋,InfluxDB的CTO组建团队开始开发一种新的,专门面向时间序列的查询语言,这个语言将不再是类SQL的,而是一种函数式的语言,它最初被命名为TICKscript。

后来,这个设计在发展的过程中经历了几次改名,由TICKscript变成IFQL(其实不只是改名,IFQL的野心很大,但与本文内容无关,可参考文末的参考文档),又由IFQL改名为Flux。
2017年11月14日,Flux被以alpha阶段随InfluxDB v1.4发布。
一年后,Flux成为了InfluxDB的默认查询语言。

无独有偶
2015年初,Prometheus发布了0.10.0,Prometheus作为当前热度排名第三的TSDB方案,一开始就没有选择类SQL查询的方案,而是开发了一种全新的函数式查询语言PromQL。

PromQL也是当下被最广泛复用的时序分析查询语言,诸如VictoriaMetrics,Nightingale等原本与Prometheus不同源的TSDB项目都实现了PromQL查询语言。
举步维艰
上述两个事件,引出了本文的主题:为什么我认为TSDB应当放弃类SQL查询语言?
接下来我将结合具体的例子论证这一观点,并带读者看到SQL是如何被一些非常简单的时序分析场景逼出能力极限。
从一个太阳能发电厂开始
假设我们从购买了一个太阳能发电厂,它会每隔一定的时间向我们的TSDB插入一个采样点,记录太阳能电板当前的输出电压和输出电流。
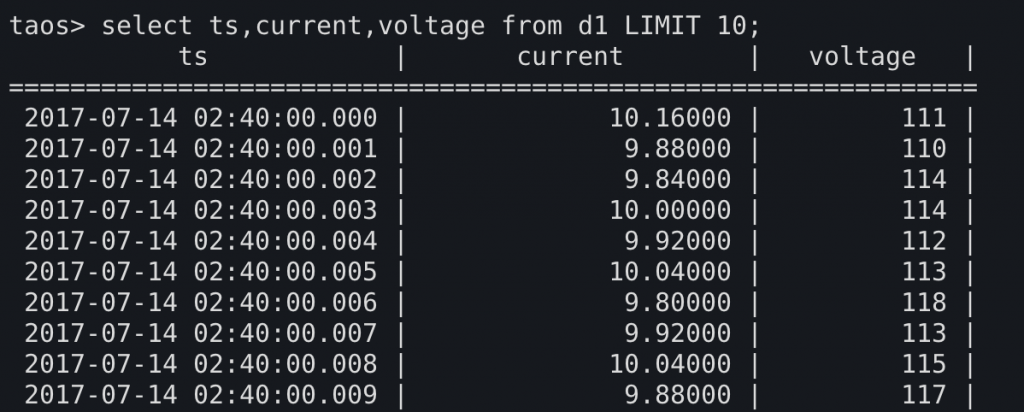
第一个常见的场景是,我们需要计算发电的功率曲线,可以用每个时间点上的current和voltage相乘,得到每个时间点上的功率。
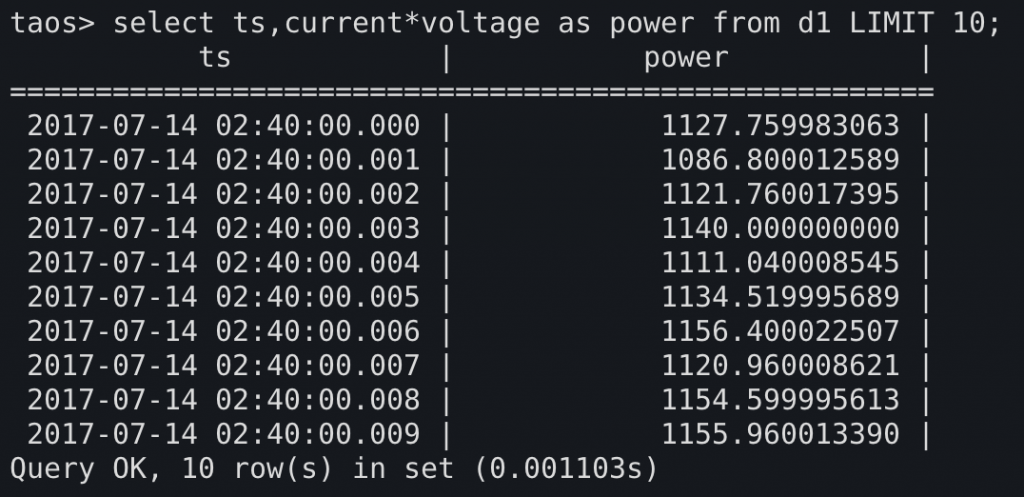
第二个太阳能发电厂的加入
随着第二个发电厂的加入,表的设计出现了一定的分歧,出现了两种可行的表结构:
方式1:将两个厂分为两个表,以表名区分厂区

方式2:新增一字段(示例中使用location字段)用以标识厂区,将两个厂的数据混存于一表中
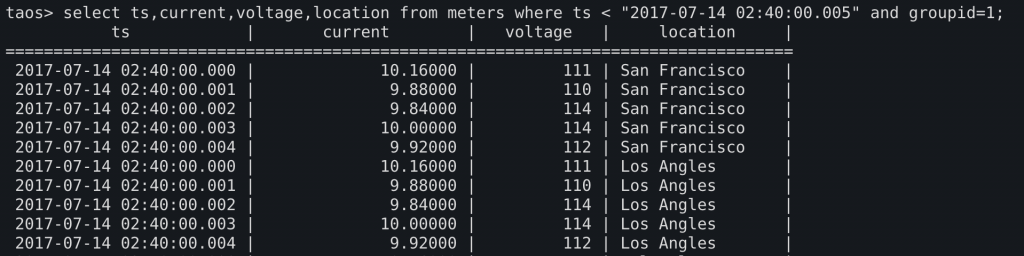
接下来,我们尝试计算两厂房的输出功率总和:
在方式1中要通过将两个表的数据JOIN到同一表中才可能进行横向的聚合计算,当前问题不大,但可以预见的是,随着厂区的数量进一步增加,这种问题会逐渐严重。当存在数百个厂区时,JOIN表和编写功率表达式的工作将变的难以接受。因此该方案目前已经受到严峻挑战。

对于方式2,由于数据原本就在一张表中,因此不存在JOIN的问题。只需要GROUP BY ts,让相同时间下不同location的点分为一组,随后SUM(current*voltage)即可。

可以看到,方式1已经陷入了困境,但方式2目前的表现看起来不错。
方式2的代价?
方式2能够适应简单的时间序列分析,但也付出了代价。
为了避免表的数量以及JOIN语句的无限制膨胀,方式2将所有可能扩展的维度(新的location,新的厂区,新的发电机型号)都以字段的方式平铺到了一张大表上。这带来一个问题:这个表在底层存储上,除了在时间上有可能具有升序外,在其余任何维度都无序。所有设备上报的采样点交替分布在整个表上,意味着即使我只想看一个设备的数据,也要承受扫描整个表的代价。
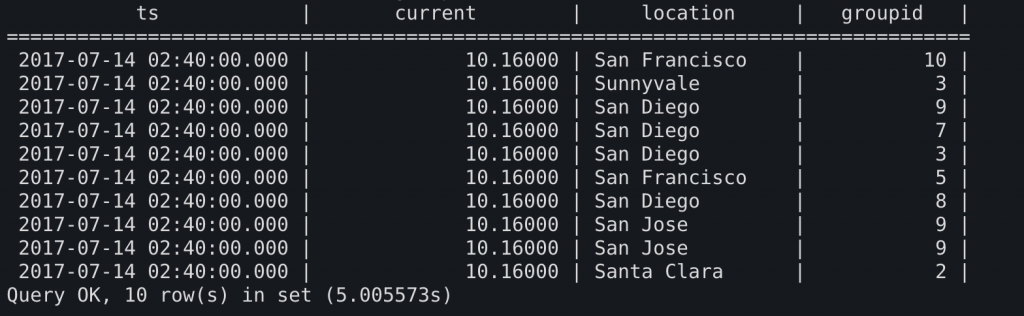
为了避免频繁的全表扫描,常见的做法是为标签字段建立索引,然而即使无视表的规模,索引也只能解决全表扫描的问题。
而在存储层,由于时间序列分布的不连续,磁盘读取依然会变的碎片化。这与采用行式或列式存储无关,因为不论在行上还是在列上,某个采样点的存储端前序和存储端后序都不会是自己的自然前序和自然后序,每一页存储被加载到内存上,都将携带大量的无用数据。
解决这个问题的常见办法就是按设备分表,让各个设备的数据分分开,不纠缠在一起,而这又将把我们带回方案1的困境。
更进一步的,时序分析上还有时间对齐(Time Alignment),滚动计算(Moving/Rolling运算,如股票分析常见的Moving Average)范式。对它们的实现也将进一步放大底层存储的困境。
为什么?
为何我们平时高频使用的SQL范式,在时序数据分析的场景如此吃瘪?
这里引出了我们文章开头的结论,即:传统的SQL范式面对的场景中,数据表的增长方向与数据的主要聚合方向相同。而对时序分析的场景来说,数据的增长方向与主要聚合方向不同。这是SQL无法胜任TSDB和时序分析查询的根本原因。
这两张图中分别展示了典型的SQL范式的表,和类时序数据的表。
可以看到SQL范式面向的聚合,通常是表内基于列的聚合,如SUM(current),COUNT(*),在SQL范式中,不论要做什么样的大规模聚合,要聚合的数据都最好是在同一个列里。当我们尝试在SQL范式下做大规模的行式(row based)聚合时(如:对每行上的一千个字段求和),就会遇到困难,因为SQL并不是面向这种场景的。
与此同时,SQL范式中的增长方向也是沿列竖向增长,而非横向增长。换言之,数据增长的方向与数据聚合的方向一致。
而在时序数据库中,时间一定会自然增长,因此时间只能作为一个列存在。
如果时间是一个保持唯一索引的列(即每个时间点在表中只出现一次),则需要将同一时刻的所有数据沿该时刻所在的行铺开。这样一来,不论分表或不分表,都会碰到前面提到的“在SQL范式下做大规模的行式(row based)聚合”的困难。开发者会发现自己连把行上的所有数字加和都充满痛苦,更遑论求标准差,分位,分类求和等。
于是,无奈但却必然的,在这些困难的限制下,出现了前文方案2中丑陋的超大表设计。在这种表里,时间戳会不断重复,所有索引列都不是唯一的,所有来源不同的采样点随意地混合在一起,连同它们的索引标签像面包屑一样沿时间零散地铺开。
而这些无疑将为TSDB的存储层性能,以及各种时序分析特性的实现带来巨大的挑战。
函数式查询语言
深入体验过Flux和PromQL的开发者一定会被它们的简洁打动,即使是熟悉SQL的人也会承认,这两门语言比SQL更适合进行时间序列分析。Prometheus的开发者曾经列出过一张PromQL和等效的SQL的对比图,直观的体现了SQL在处理时序问题上的冗长。

采用了函数式查询语言的TSDB至少还有以下几个方面的优点:
- 嵌套多层子查询的查询语句更加易于编写和阅读
- 无需因语言限制而如前文一样设计特殊的表结构来实现查询
- 无需因语言限制而打散连续的时间序列,能够连续存储并高效读取
- 无需担心实现新特性会破坏SQL标准或SQL设计理念,设计包袱小,相应的语言也会更简洁
- 脱离“行列”结构,将时间戳从普通的“数据列”提升为TS存储中的一等公民
总结
本文逐步阐述了为什么我认为类SQL范式的语言不适合作为TSDB的查询语言。这个问题的根源在于SQL范式设计中的聚合方向与时间序列常用的聚合方向不同。
而由于篇幅有限,文末简要介绍了函数式查询语言,但没有具体展开。如有兴趣可以参考文末的参考文档,其中编号1为InfluxDB的Flux语言简介,编号3、4为Prometheus的PromQL的理念和使用简介。
参考文档:
[1]. The Design of IFQL, the New Influx Functional Query Language
[2]. Announcing Flux (formerly IFQL) – A New Query Language and Engine of InfluxDB
[3]. https://zhenghe.gitbook.io/open-courses/database-design/prometheus