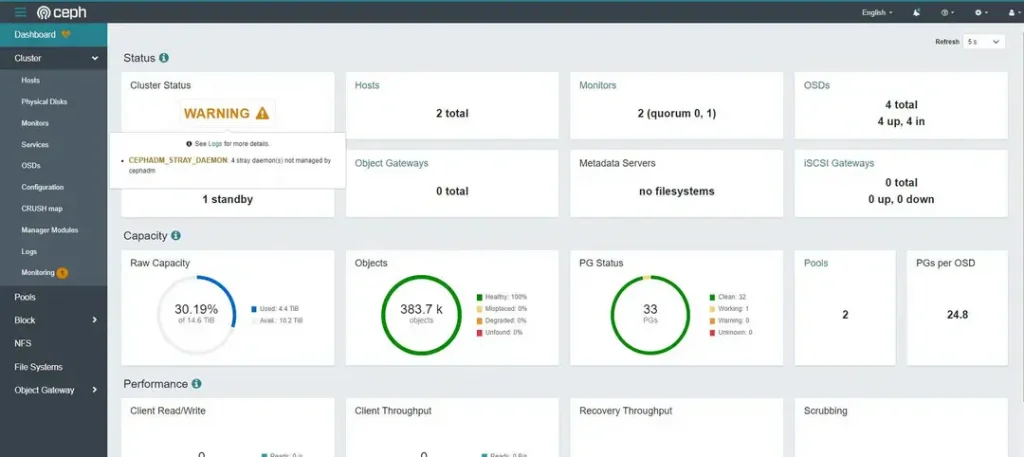
如果使用Ceph作为家庭存储,则节点数量通常为2-3个,并且质量参差不齐,废旧的笔记本,吃灰的树莓派,都可能作为Ceph的成员加入到集群中。在这种集群中,如果出现了重要的节点丢失,无法通过常规的Recovery恢复数据时,要如何处置?
前言
我有一个两节点的Ceph集群,已经正常运行了一年多,成员是一个树莓派和一个HP Gen8四盘位服务器
春节前夕,准备出去滑雪,发现相机的SD卡不见了。原来是之前搭建Ceph集群的时候,把相机的SD卡拿去给树莓派用了。这下春节期间快递都停了,现买SD卡不太好买,有点头疼。
好在我的Ceph集群里一共有两张SD卡,一个在树莓派上装了系统,另一个在Gen8上,做liveCD介质,于是决定把它拔下来用,美滋滋。
这里简单介绍一下今天的主角,这台Gen8,他里面有四盘位,在我的Ceph集群里装载(唯四的)4块OSD,光驱位是SSD位做系统盘,主板上有一个SD卡读卡器做liveCD用于灾难情况恢复系统。

lsblk检查挂载,开箱,热拔卡,一气呵成,看看服务没什么问题,就格式化掉SD卡,出发去玩了。一路无话,等到旅游回来后,上电才发现Gen8启动不了了。
仔细回忆,原来今年年初我为了实验Ceph缓存,把系统盘从SSD改为到SD卡了。
也就是说我一顿操作,把Gen8的系统擦掉了。
思路整理
简单整理了一下现状
在2节点的Ceph集群中,丢失一个节点则导致无法选主,树莓派上的mon无法启动
所有OSD都在故障节点上,虽然数据暂时还没有丢失,但都是不可访问的,也谈不上recovery。
恢复的思路很清晰,先恢复树莓派上的mon,再给Gen8安装新系统,再用树莓派的mon恢复Gen8上的mon,然后直接用恢复的mon接管之前的osd。
理论上ip和hostname都没变,也就不涉及到CRUSH map的更新,新的mon接管旧的osd后就可以直接使用,集群就能恢复之前的样子了。
无主的集群
当集群无法选主的时候,会报出类似如下的异常
2020-10-28 00:38:20.817 7fc3d040a700 1 mon.bean@3(probing) e7 handle_auth_request failed to assign global_id 2020-10-28 00:38:21.449 7fc3d040a700 1 mon.bean@3(probing) e7 handle_auth_request failed to assign global_id 2020-10-28 00:38:22.637 7fc3d040a700 1 mon.bean@3(probing) e7 handle_auth_request failed to assign global_id
这是因为分布式集群中需要多数活数才能完成选主,而我的集群中只有两个节点,挂掉一个就已经失去了多数。
此时,需要调整monmap,将已经丢失的节点临时去掉,使得还正常的节点上的ceph可以正常启动。
$ ceph-mon -i {this mon id} --mon-data {mon data path} --extract-monmap /tmp/monmap
$ monmaptool /tmp/monmap --rm {lost mon id}
$ ceph-mon -i {this mon id} --mon-data {mon data path} --inject-monmap /tmp/monmap
$ systemctl restart {mon service}
例如
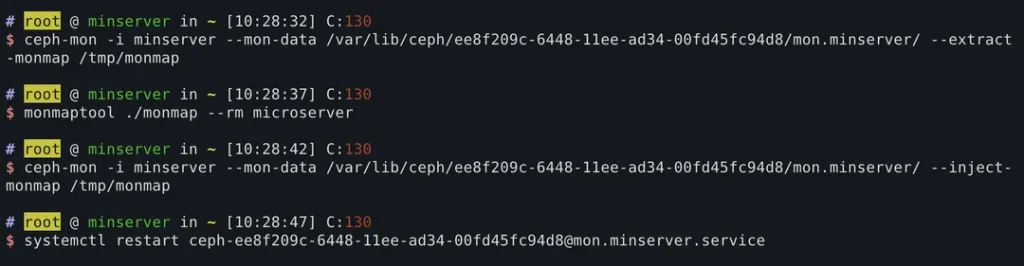
完成操作后,树莓派上的ceph mon恢复了运行
集群恢复
重装了Gen8的系统后,下一步就是恢复Gen8的ceph服务。
我部署ceph时用的是cephadm,cephadm创建的每个集群都有一个统一的ssh key,用于跨节点的操作。例如,官方文档中向ceph集群增加节点时,只需要拷贝key到对端,再将对端节点id加入到ceph,cephadm就会自动到对端部署各种服务

那丢失节点的恢复,理论上也只需要将key拷贝到新系统上,cephadm就会自动将服务部署上去

试了一下,果然,服务陆续在恢复节点上启动了

OSD重加入
比较奇怪的是,集群的osd虽然被识别了,但没有自动加入到恢复的集群中。也就是osd的服务没有自动生成和启动。
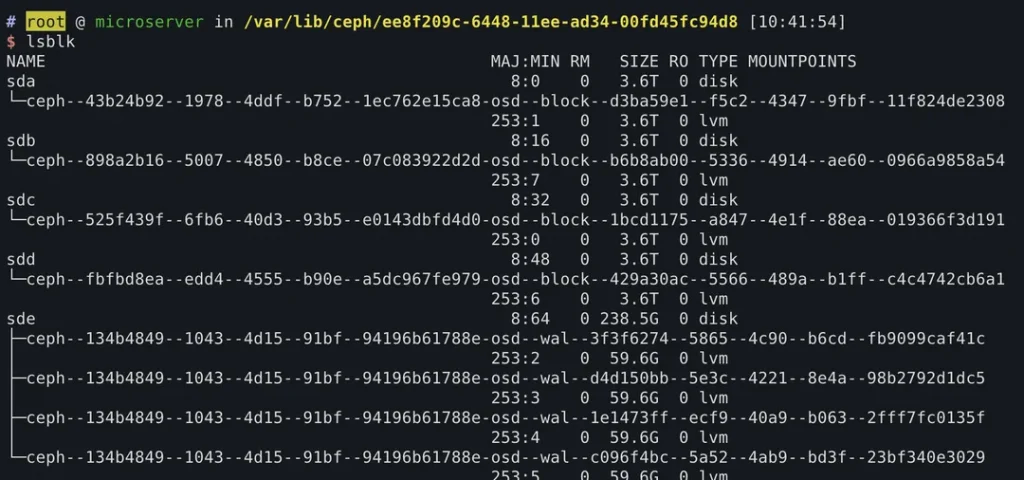
补充执行命令,将已识别的osd启用
$ ceph-volume lvm activate --all
集群恢复正常,唯一的告警是游离的service,因为上面这条命令是裸的ceph命令,创建的service不受cephadm托管。
当然我之前也试过cephadm的volume命令,报错了,大概说的是没找到osd的挂载路径,不过我懒得查原因,就直接用这个命令搞定了。