TL;DR
在一次对服务问题的排查中,我们发现某个k8s的worker CPU处于Idle状态,但Load Average却异常高,这种情况是反直觉的。后续通过对容器绑核情况的排查,最终定位到问题来源于K8s的Static CPU管理策略。
叛逆的LoadAvg
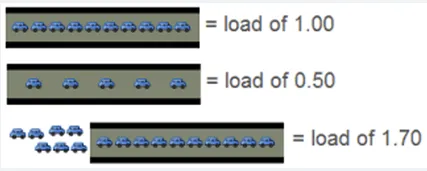
先介绍一下,Load Average是一个常见的用于衡量系统压力的指标。一般来说,Load avg恰好等于机器的CPU核心数的时候是最好的,这说明没有进程在等待CPU,也没有CPU在空转。Load avg越大,则代表正在排队等待CPU的进程越多。
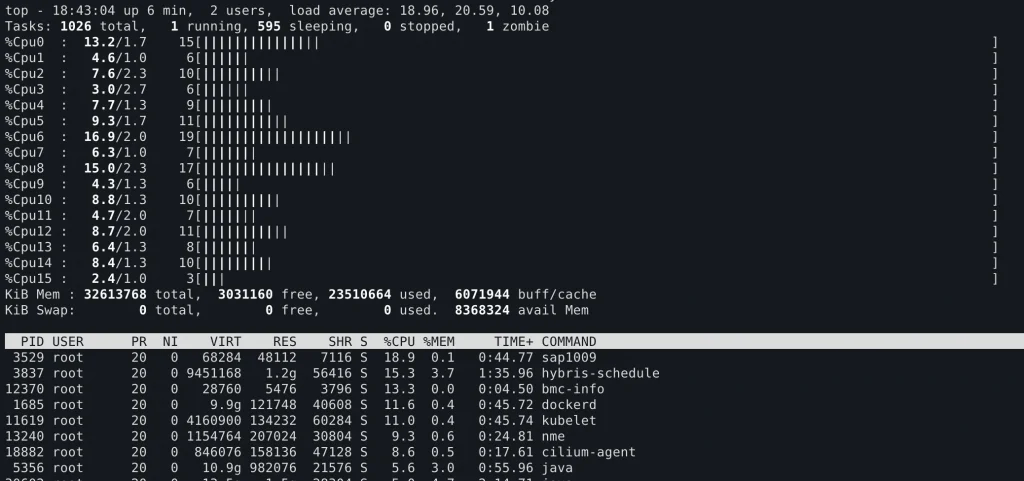
进入正文:在一次对Pod状态异常的排查中意外发现了下面的现象:在一个16 vCPU的k8s worker上,87%的CPU时间是空闲的,但LoadAvg却高达133。说明CPU整体空闲,但却有超过100的线程在等待CPU。
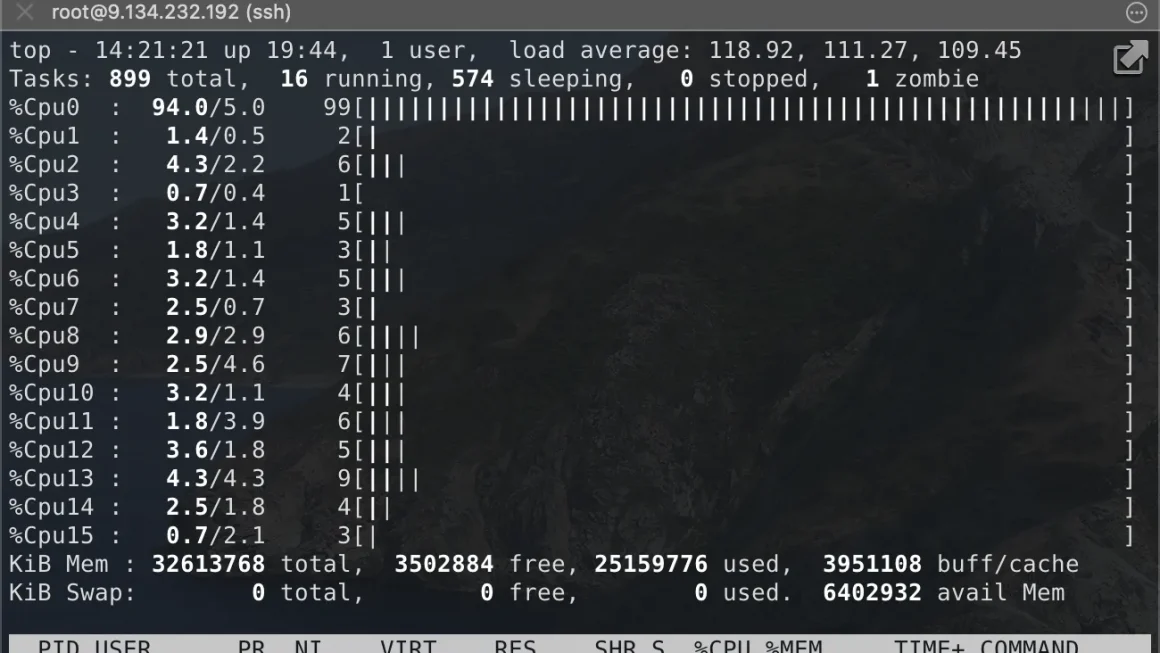
毋庸置疑,哪怕vCPU底层是与其他虚机共享的,也不可能有如此严重的CPU争抢,问题一定是出在了虚拟机内部的CPU时间分配上。马上查看各个核心的压力分布,没想到一进来就看到:

不好意思放错图了:
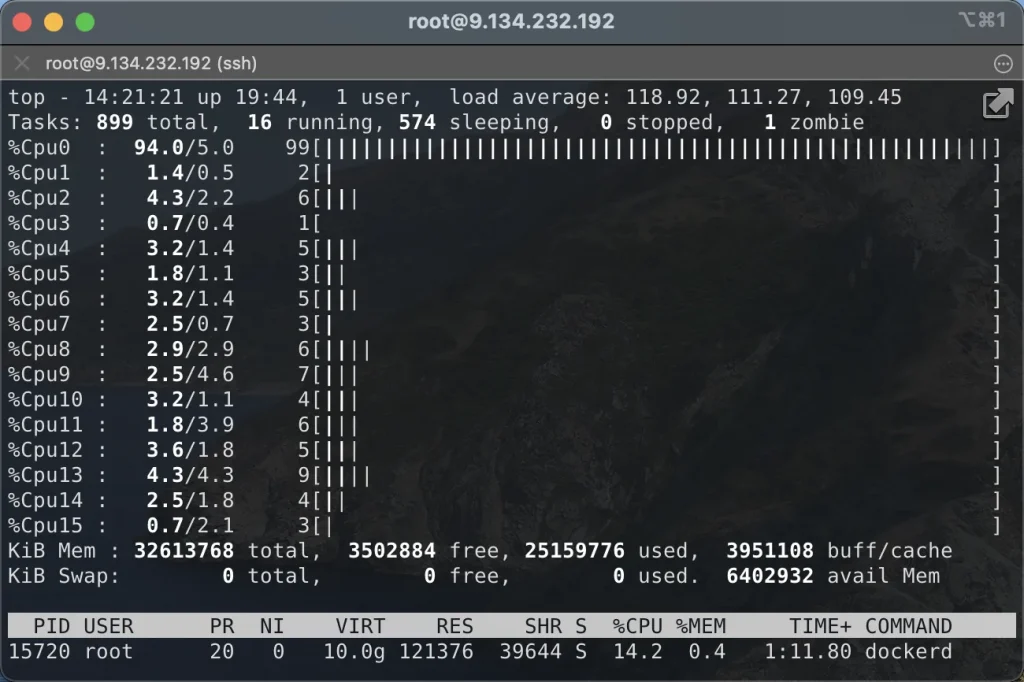
放错了,但没完全放错,甚至可以说是一模一样,这就是教科书级别的一核有难N核围观。
绑核追凶
Linux内核提供了功能强大的CPUSet子系统,可以指定各个进程对多线程CPU的核心亲和性(Affinity)。
简单地说,CPU 亲和性(affinity)就是进程要在某个给定的 CPU 上尽量长时间地运行而不被迁移到其他处理器的倾向性。更多介绍可参考Linux中CPU亲和性(affinity)。
这个功能的初衷是便于计算密集型的应用程序设置固定的核心,以避免频繁切换核心导致的上下文切换和CPU缓存同步。这种操作也被称为绑核
回到本Case中,CPU0的压力异常巨大,且等待运行的进程异常的多,可其他CPU却非常空闲。
那么显而易见,这个节点上发生了绑核,可究竟是谁绑了核?
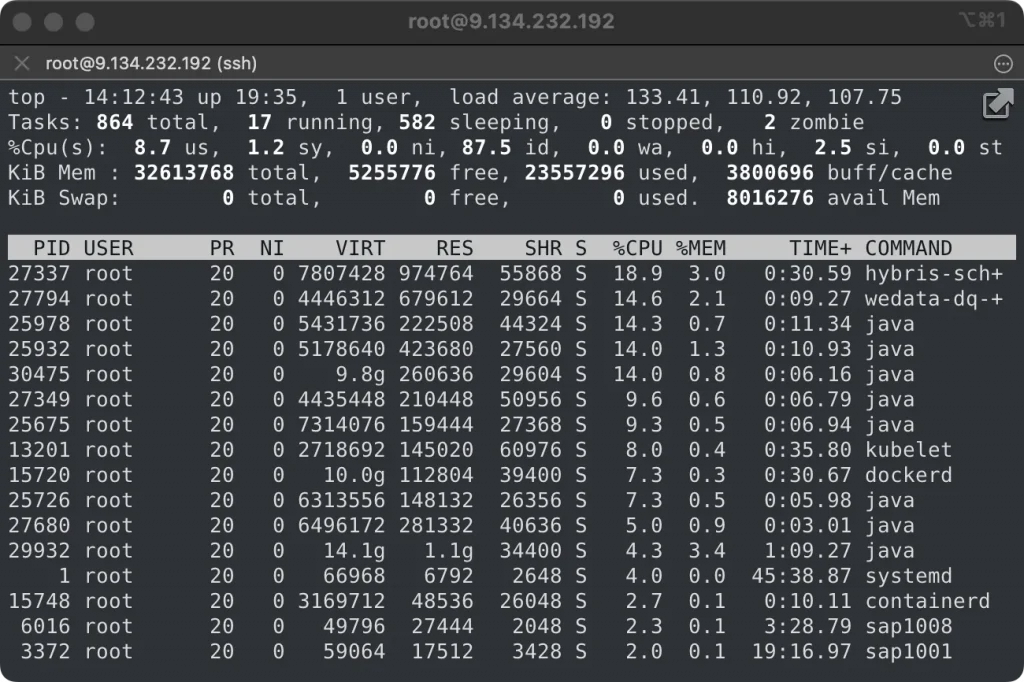
首先执行top,按F进入列选择菜单,选中P(Last Used Core)并退出,就看到了有大量的java程序跑在0号核心上。因此,最初我们怀疑业务的jvm设置了绑核。不过登录具体的容器后,发现并没有任何绑核的jvm参数,因此jvm的嫌疑被排除
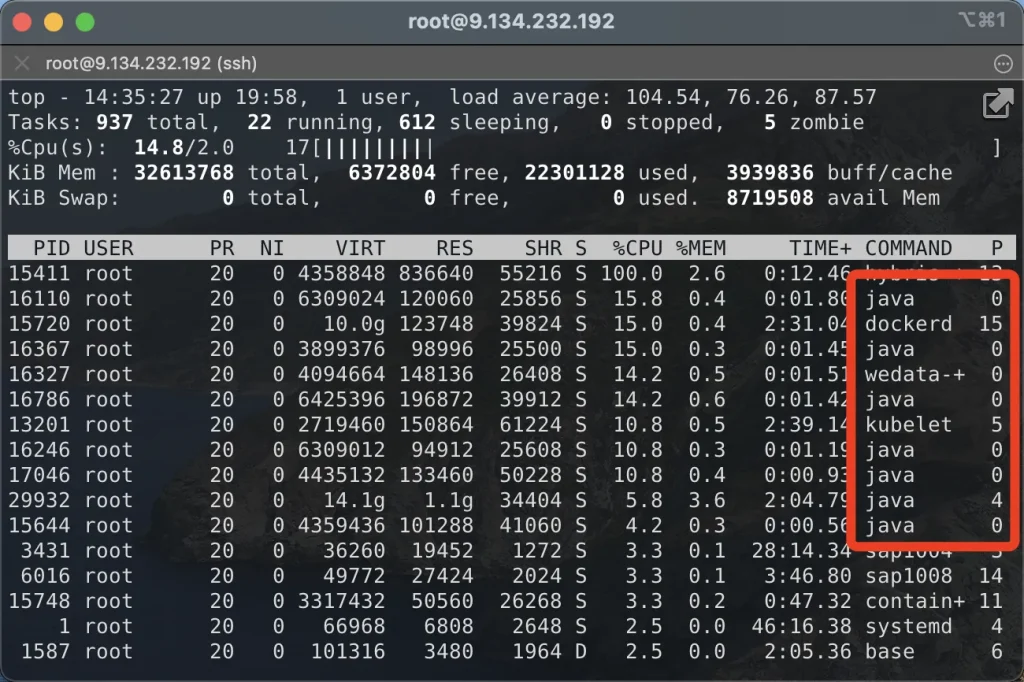
随后执行了docker inspect命令查看各个容器的绑核情况,发现大量的container被绑定了核心0,那么行凶的人就初步定位到了,是docker。
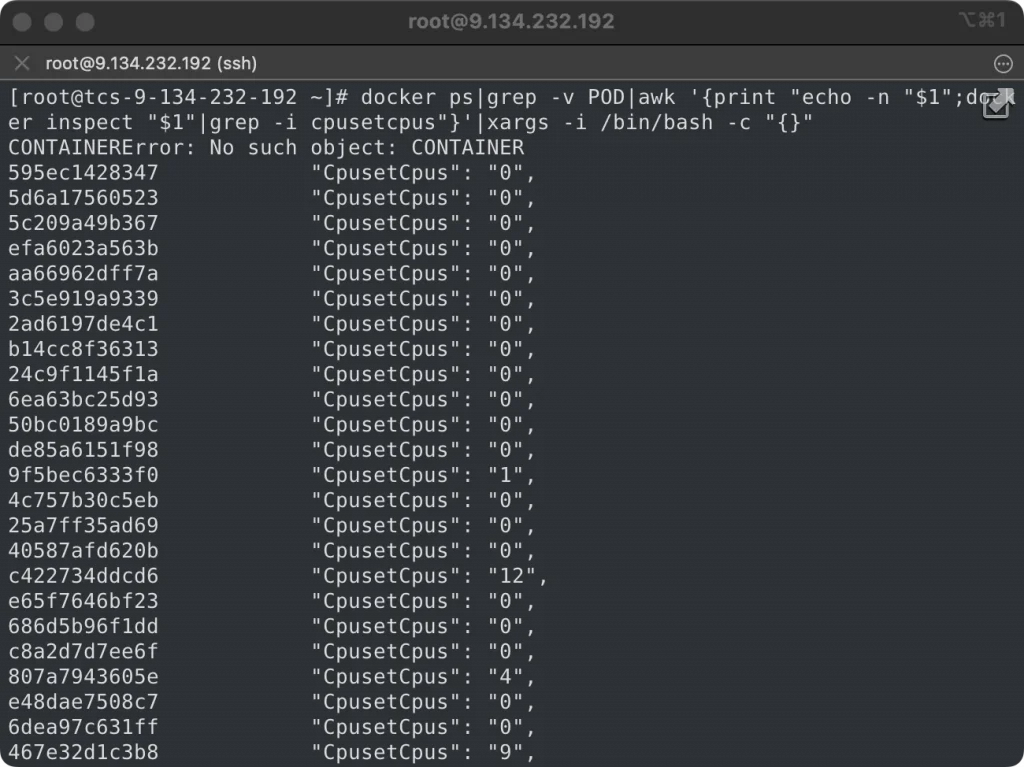
可众所周知,在K8s中docker只是一个唯命是从的傀儡,绑核的主谋另有他人。
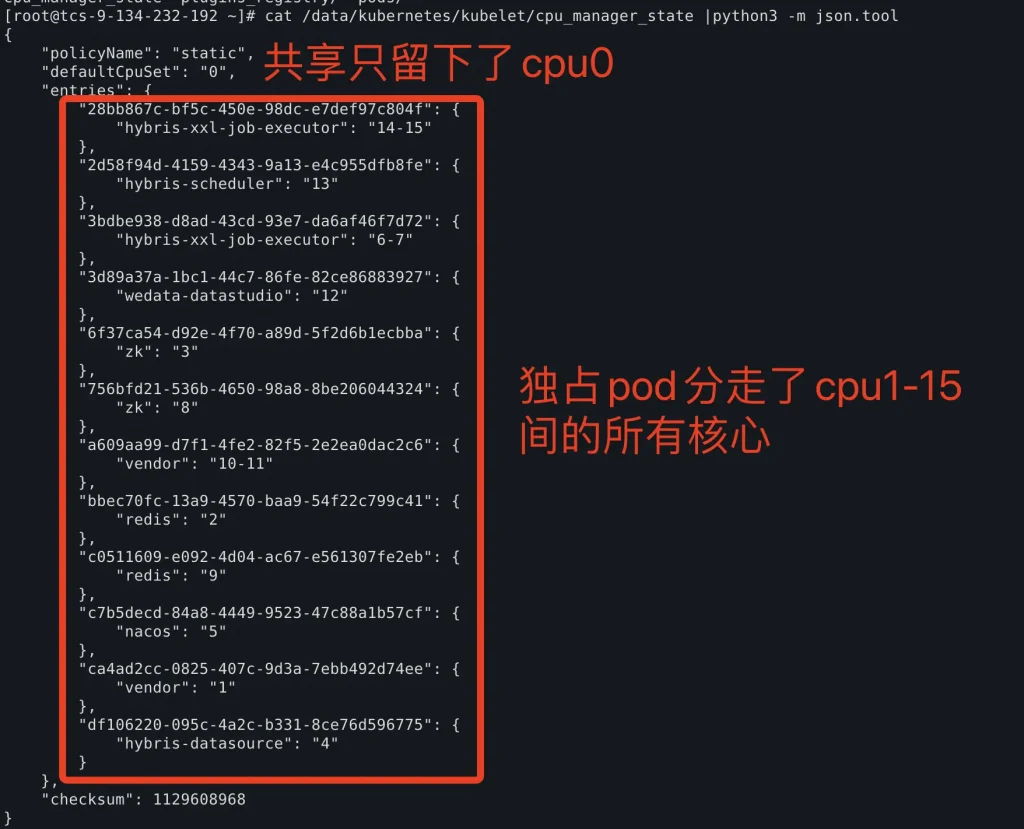
在K8s API Resource上捕风捉影地走了一系列弯路之后,最终还是回头将嫌疑定位在了对应节点的kubelet上。排查到一个隐秘角落的描述文件后,才发现原来是kubelet的defaultCpuSet被锁定到了0号核心,才导致如此多的容器都挤在0核上排队。
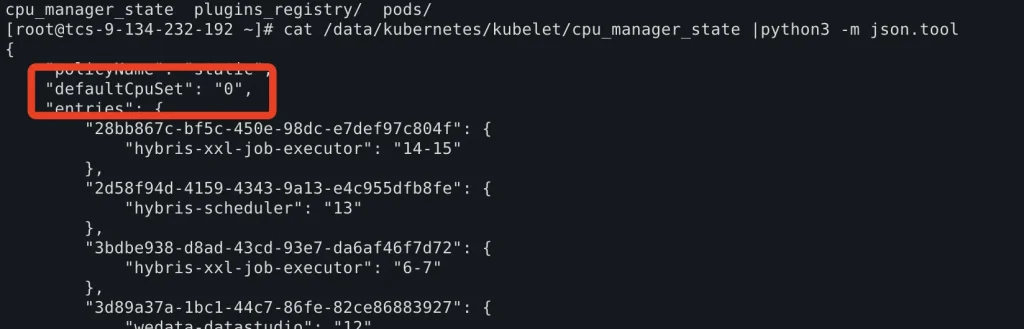
但这个文件并非是配置文件,而是kubelet动态生成的文件。那么接下来的问题就是,这个文件是如何生成的?或者说defaultCpuSet是如何被确定的?
幕后的CPU管理策略
根据K8s官方文档控制节点上的 CPU 管理策略的描述,K8s在1.12(远古版本)中引入了kubelet上的CPU管理策略配置。并在原有的、基于CFS实现的、较为模糊的CPU调度策略的基础上,新增了基于CPUSet实现的更加精确的CPU管理策略,被称为static策略。
static策略是如何运作的呢?他将节点上的CPU资源分成了两类资源池,一类是共享资源池,另一类是独占资源池。顾名思义,共享就是大家一起来,独占就是垄断使用权。
可这和刚刚那个defaultCpuSet有什么关系呢?聪明的小伙伴可能已经想到了,defaultCpuSet就是这里所说的共享资源池,那为什么共享资源池只有一个cpu0呢?当然是因为其他的CPU都被想独占CPU的pod划走了。
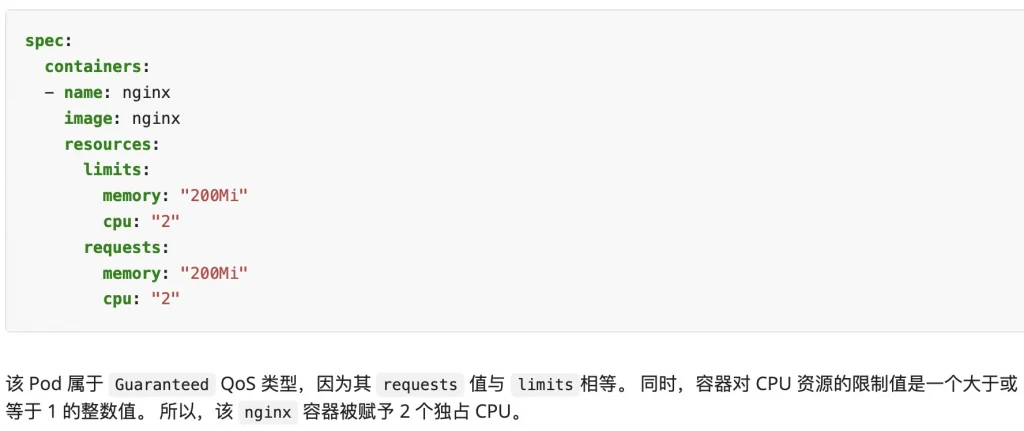
那么根据static策略,哪些pod有权独占CPU呢?根据文档的描述,只有当Pod的QoS等级为Guaranteed时,也即Pod的Limits和Requests相等时,该Pod申请的CPU会被划定为独占CPU。这很合理,毕竟这个等级的名字就叫Guaranteed。(注:此处其实还要求Pod申请的资源为整数,如果某Guaranteed等级的Pod申请的资源为小数,如500m核,也不会绑核。)
行文至此,问题的根源已经找到了,那么怎么解决这个问题呢?
解决办法
第一种解决办法是调整pod的QoS等级,只要让requests稍微小于limits,Pod的等级就会被调整为Burstable,就不会再独占资源。毕竟一大堆util=5%的服务在独占cpu,然后cpu0在疯狂加班的人间悲剧是我们都不希望看到的,这种人世间的剥削还是不要在数字世界重演了。(笑)
第二种解决办法也是相对简单的。前文说过,k8s提供了两种策略,除了精确控制的static策略外,还有一种通过CPU时间片进行模糊控制的none策略。只需要修改kubelet配置文件,将cpu管理策略改为none:
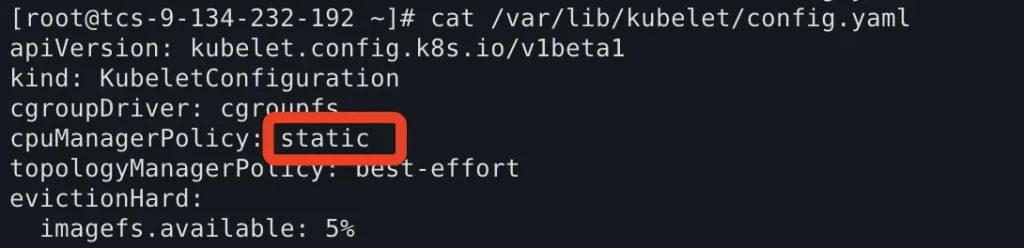
然后依次重启docker和kubelet,也可以解决该问题。
最后执行Top查看CPU压力分布,确认问题解决。